
GPU 자원을 추론 API로 바꾸는 법
- 5월 29일
- 6분 분량

유휴 GPU를 API Capacity로 바꾸는 Distributed GPU Cloud 이야기, 그리고 Ray
💡 핵심 메시지 "아무리 좋은 GPU도 API로 전환되지 않으면 가치가 없습니다." Aircloud는 인프라 하드웨어가 실제 서비스 레이어로 도달할 수 있도록 런타임부터 플랫폼 계층까지의 모든 파이프라인을 연결합니다.
들어가며
요즘 AI 인프라를 이야기하면 가장 먼저 나오는 키워드는 GPU shortage입니다. H100을 얼마나 확보했는지, B200 수급은 어떤지, 데이터센터 전력은 충분한지 같은 이야기가 자연스럽게 따라옵니다. 하지만 실제 서비스를 만들고 운영하다 보면, 문제는 단순히 “GPU가 부족하다”에서 끝나지 않습니다.
GPU가 부족한 것도 맞지만, 동시에 이미 존재하는 GPU가 항상 잘 활용되고 있는 것도 아닙니다.
어떤 GPU는 요청이 몰려 과부하 상태이고, 어떤 GPU는 비어 있습니다. 평균 GPU utilization은 괜찮아 보여도 실제로는 일부 자원만 바쁘고 나머지는 놀고 있는 경우도 있습니다. 같은 프롬프트가 반복되는 요청인데도 매번 다른 replica로 흩어져서 이미 계산한 prefill을 다시 수행하기도 합니다.
결국 AI 인프라의 핵심 질문은 이렇게 바뀌고 있습니다.
"GPU를 얼마나 많이 가지고 있는가가 아니라, GPU를 얼마나 유용한 output으로 바꿀 수 있는가."
이 글에서는 AIEEV가 Aircloud를 만들면서 고민해온 내용들을 정리하고, 왜 Ray를 선택했는지, 그리고 이를 활용해 흩어진 GPU 자원을 어떻게 안정적인 API capacity로 전환하고 있는지 살펴보겠습니다.
1. 추론 시대에는 왜 GPU 운영이 더 어려워질까요?
AI 패러다임이 거대한 베이스 모델을 고도화하는 ‘학습(Training)의 시대’에서, 이를 실제 서비스에 녹여내 대규모 트래픽을 감당하는 ‘추론(Inference)의 시대’로 완전히 전환되었습니다. 인프라를 바라보는 관점 역시 이에 맞춰 통두째 바뀌어야 합니다.
학습과 추론은 비용 구조부터 근본적으로 다르기 때문입니다.
기존의 학습은 대규모 GPU 클러스터를 단기간에 집중적으로 확보하여 모델을 빌드하는 등, 큰 비용이 일회성·선불성으로 지출되는 성격이 강했습니다. 반면 본격적인 서비스 레이어인 추론은 유저가 요청을 보낼 때마다, 에이전트가 작동할 때마다, 토큰이 생성될 때마다 비용이 지속적이고 누적적으로 발생합니다. 즉, 서비스가 확장될수록 인프라 비용이 선형을 넘어 기하급수적으로 불어나는 구조입니다.
따라서 추론 중심의 인프라에서는 하드웨어의 단순 연산력을 넘어, 다음과 같은 비즈니스 및 기술 지표들이 운영의 핵심으로 떠오릅니다.
지표 | 의미 |
$ / request | 요청 하나를 처리하는 비용 |
$ / token | 토큰 하나를 생성하는 비용 |
TTFT | 첫 토큰이 나오기까지 걸리는 시간 (Time to First Token) |
TPOT | 토큰 간 생성 지연시간 (Time Per Output Token) |
Throughput | 단위 시간당 처리 가능한 요청 또는 토큰 수 |
Cache hit ratio | KV cache나 prefix cache를 얼마나 잘 재사용하는지 |
API uptime | API가 얼마나 안정적으로 살아 있는지 |
GPU 서버를 많이 확보했다고 해서 이 지표들이 자동으로 좋아지지는 않습니다. 특히 LLM inference에서는 routing, batching, cache, placement, autoscaling을 얼마나 잘 조합하느냐에 따라 성능과 비용이 결정됩니다.
2. GPU 서버와 추론 API 사이에는 무엇이 필요할까요?
GPU는 그저 하드웨어 인프라일 뿐입니다. 유저가 체감하는 것은 하드웨어 그 자체가 아니라, 내가 호출한 API가 얼마나 빠르게 응답하고 안정적으로 유지되는가 하는 서비스 경험입니다.
GPU 서버를 API 서비스로 전환하려면, 아래와 같이 인프라와 애플리케이션을 이어주는 네 가지 계층이 유기적으로 맞물려야 합니다.
계층 | 역할 |
Compute | 범용 CPU 및 AI 가속기 (GPU, NPU, TPU 등) |
Memory / Storage | VRAM, HBM, KV cache, 모델 파일(Artifact), 체크포인트 관리 |
Network | 데이터센터 내부 네트워크, 외부 인프라 및 Edge 연결 대역폭 |
Runtime / Orchestration | 어떤 AI 연산 작업을 어느 하드웨어에, 얼마만큼 할당하여 실행할지 결정하는 계층 |
전통적인 클라우드 생태계에서 가장 상위 계층인 Orchestration을 담당해 온 프레임워크는 단연 Kubernetes입니다.
하지만 LLM 추론 워크로드로 오면 쿠버네티스만으로는 한계가 드러납니다.
LLM 추론은 일반적인 웹 서비스처럼 단순히 '컨테이너 껍데기'만 몇 개 더 띄운다고 해결되지 않습니다. 모델의 거대한 가중치(Weight)를 GPU 메모리에 상시 올려두어야 하고, 수많은 요청의 컨텍스트 캐시를 실시간으로 공유해야 하며, 모델 내부의 특정 연산 단위를 동적으로 쪼개어 스케줄링해야 합니다.
즉, 인프라 단위를 넘어 'AI 애플리케이션 소스코드 레벨'과 '하드웨어 자원'이 정밀하게 소통하는 특수한 실행 환경이 필요합니다.
💡 쿠버네티스가 container/pod 단위를 스케줄링한다면, AI 워크로드에는 모델 실행 단위를 분산 환경에 직접 스케줄링해 줄 수 있는 새로운 솔루션이 필요합니다. 여기서 Ray가 등장합니다.
3. Ray는 어떤 역할을 하나요?

Ray는 Python 코드를 분산 환경에서 실행하기 위한 runtime입니다. Ray 생태계는 구조화되어 있습니다. 모든 분산 처리를 밑단에서 지탱하는 핵심 엔진을 Ray Core라고 부르며, 이 엔진 위에 데이터 처리(Ray Data), 서빙(Ray Serve) 등과 같은 기능들이 확장 레이어로 얹어지는 형태입니다. Ray Core에는 세 가지 중요한 개념이 있습니다.
Task
가장 단순한 실행 단위입니다. Python 함수에 @ray.remote 를 붙이고 .remote() 로 호출하면 클러스터 어딘가의 worker process에서 분산 실행됩니다.
Actor
상태를 가진 분산 객체입니다. LLM 서빙에서는 모델을 매 요청마다 새로 로드하면 안 되므로, 모델 weight를 GPU memory에 올린 채 계속 살아있는 long-lived execution unit을 표현할 때 이 Actor 모델이 반드시 필요합니다.
Object
Task나 Actor의 결과물은 대형 Object Store에 저장되며 ObjectRef 를 통해 참조됩니다. 다만, node 간 이동 시 네트워크 비용이 발생하므로 edge GPU 환경에서는 주의가 필요합니다.
⚡ 정리하면: Ray는 모든 인프라 문제를 해결하는 마법이 아니라, AI 워크로드를 분산 환경에서 실행하기 좋게 추상화해주는 runtime에 가깝습니다.
4. Ray Serve는 모델을 API로 바꾸는 serving layer입니다
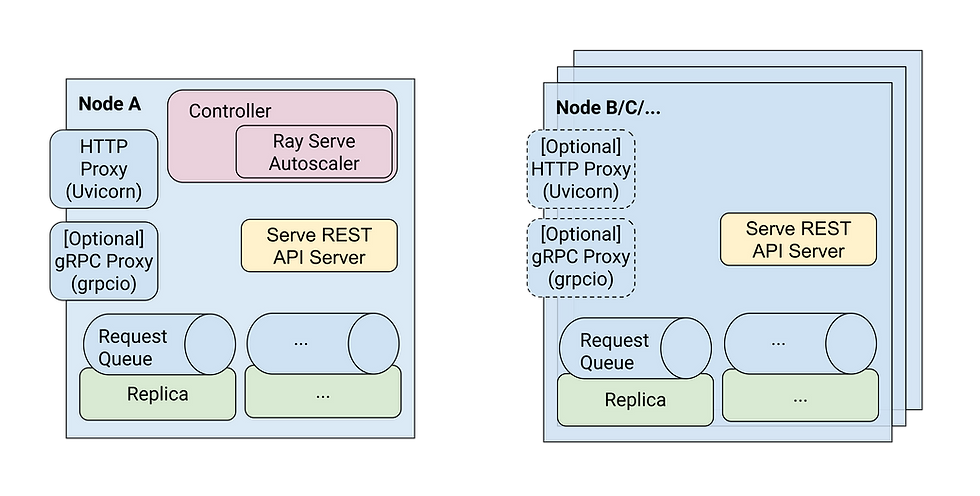
Ray Core가 분산 실행의 토대 기술을 제공한다면, Ray Serve는 그 위에서 모델을 API로 서빙하기 위한 프레임워크입니다.
구성요소 | 역할 |
Proxy | 외부 HTTP/gRPC 요청을 받는 진입점 |
Controller | deployment와 replica 상태를 관리하는 control plane |
Deployment | 모델 또는 비즈니스 로직의 서빙 단위 |
Replica | 실제 요청을 처리하는 actor instance (모델 로드 및 KV cache 관리) |
Queue | replica가 바쁠 때 요청이 대기하는 지점 |
Autoscaler | traffic과 queue 상태를 보고 replica 수를 조절 |
특히 LLM의 경우에는 모델 로딩과 warm-up 과정의 오버헤드가 크기 때문에, Ray Serve를 통해 요청을 실제 처리하는 Replica들의 lifecycle을 영리하게 관리하는 것이 latency와 cost 절감의 핵심입니다.
5. Ray Serve LLM은 LLM serving을 위한 확장 계층입니다

Ray Serve LLM은 Ray Serve 위에 올라가는 LLM 전용 서빙 레이어입니다.
실제 토큰 생성, KV 캐시 관리, continuous batching 같은 Low-level 연산은 vLLM 같은 서빙엔진이 담당하고, Ray Serve LLM은 이 엔진들을 어디에 띄우고 어떤 엔드포인트로 라우팅할지 결정하는 Orchestration을 담당합니다.
Ray Serve LLM: OpenAI-compatible API, 라우팅, deployment, replica 수명주기, 오토스케일링 관리
vLLM / Inference Engine: Token generation, KV cache, continuous batching, GPU 연산 실행
PyTorch / NCCL / CUDA: 텐서 연산, 대규모 GPU 간 통신(Collective communication), 커널 실행
6. KubeRay: Kubernetes 환경과의 심리스한 결합
앞서 보았듯 LLM 추론 영역에서 Ray 생태계(Core → Serve → LLM)는 매우 강력한 런타임을 제공합니다. 하지만 엔터프라이즈 환경에서 이 분산 클러스터를 안정적으로 배포하고, 모니터링하며, 기존의 마이크로서비스들과 격리·운영하기 위해서는 결국 클라우드 네이티브의 표준인 Kubernetes 인프라가 필요합니다.
이 두 세계를 연결하는 고리가 바로 KubeRay입니다.
KubeRay는 Kubernetes 위에서 선언적으로 Ray 클러스터(Ray Head, Ray Worker)의 라이프사이클을 관리하는 오퍼레이터(Operator)입니다. 즉, 인프라의 베이스 레이어(Kubernetes)와 AI 애플리케이션의 분산 실행 레이어(Ray)를 결합하여 개발자가 인프라 걱정 없이 서빙에만 집중할 수 있는 환경을 만듭니다.
🛠️ 문제는 '환경의 불확실성'입니다. 완벽하게 통제된 단일 데이터센터 환경이라면 KubeRay와 Ray Serve의 기본 아키텍처로 충분합니다. 하지만 Aircloud가 마주한 현실은 데이터센터급 인프라부터 소규모 커스텀 클러스터, 사내 AI 워크스테이션, 그리고 곳곳에 파편화된 개인용(Consumer) GPU까지 하드웨어 구조(Topology)와 인프라의 규모가 완전히 제각각이라는 점입니다. 이 때문에 모든 GPU에 동일한 서빙 런타임 전략을 고집하는 것은 불가능합니다. Aircloud는 이 하드웨어 불확실성을 해결하기 위해, 연결된 자원의 규모와 네트워크 상태를 실시간으로 파악합니다. 그리고 스케줄링부터 라우팅, 병렬화 기법에 이르기까지 최적의 서빙 전략을 'Workload & Topology Aware'하게 조합하여 문제를 해결합니다.
7. Aircloud 전략
① 인프라 규모별 맞춤형 스케줄링 및 병렬화
Aircloud는 유입된 워크로드의 특성과 GPU 장비의 하드웨어 토폴로지를 실시간으로 파악하여, 해당 작업이 가장 효율적으로 돌아갈 수 있는 최적의 레이어에 스케줄링하고 병렬화 전략을 선택 적용합니다.
GPU 인프라 체급 | Aircloud가 적용하는 토폴로지 기반 최적화 전략 |
고속 Network Fabric으로 연결된 데이터센터 및 소규모 클러스터 | • 고성능 분산 기법 (Data Parallel Attention, Expert Parallelism) • Prefill-Decode Disaggregation (PD 분리 서빙) 적극 스케줄링 |
단일 Node (Multi-GPU) AI 워크스테이션 환경 | • 고속 내부 대역폭을 활용한 Tensor Parallelism, Pipeline Parallelism • 메모리 절감을 위한 CPU/KV Offloading 조합 |
지리적으로 분산된 Edge / 개인용(Consumer) GPU Pool | • 무리한 노드 간 통신을 지양하는 Lightweight 단일 Node 서빙 • 오버헤드를 최소화한 Workload-aware Placement |
예를 들어, 통신 대역폭이 보장되는 클러스터급 인프라에는 연산 효율을 극대화하는 분산 전략을 적용하지만, 독립적인 단일 워크스테이션이나 Consumer GPU 환경에서는 개별 GPU 내부에서 최대한 처리할수있는 워크로드를 스케줄링하여 네트워크 병목을 원천 차단합니다.
② 지능형 라우팅과 Prefill-Decode 최적화
이전 포스트에서 한 번 이야기했듯이, LLM 추론 단계는 크게 두 가지(모델 로딩을 제외하면)로 나뉩니다. 다시 리마인드해보면 다음과 같습니다.
Prefill: 입력 prompt 전체를 읽고 고부하 attention 계산을 통해 KV cache를 만드는 단계 (Compute-heavy)
Decode: 만들어진 KV cache를 보면서 토큰을 하나씩 생성하는 단계 (Memory bandwidth-heavy)
Aircloud는 연결된 인프라의 네트워크 상태에 따라, 이 Prefill과 Decode 단계를 처리하는 라우팅 메커니즘을 완전히 다르게 가져갑니다.
초고속 네트워크가 보장되는 클러스터급 환경 (PD Disaggregation): Prefill에서 생성된 대규모 KV cache를 지연 없이 넘길 수 있는 네트워크가 갖춰진 경우, Aircloud는 Prefill 전용 노드와 Decode 전용 노드를 물리적으로 분리(Disaggregation)하여 스케줄링합니다. 이를 통해 전체 시스템의 Throughput을 극한으로 끌어올립니다.
네트워크가 느슨한 일반 Edge 및 단일 GPU 환경 (Prefix-Aware Routing): 네트워크를 통해 고용량 KV cache를 이동시키는 것 자체가 거대한 오버헤드가 됩니다. 따라서 Aircloud는 자원을 이동시키는 대신, 기존에 동일한 System Prompt나 Context 캐시(KV cache)를 들고 있을 가능성이 가장 높은 웜(Warm) Replica를 찾아 요청을 찔러주는 Prefix-aware routing을 수행합니다. Cache Miss를 최소화하여 네트워크 비용 없이 TTFT를 획기적으로 단축시킵니다.
💡 결국 Aircloud의 핵심은 어떤 사양의 인프라가 유입되더라도, 플랫폼이 자원의 네트워크 대역폭과 연산 능력을 실시간으로 파악하여 가장 높은 비용 효율과 퍼포먼스를 낼 수 있는 최적의 아키텍처(Data Parallel, PD Disaggregation, Prefix-Aware Routing 등)를 동적으로 구성한다는 점에 있습니다.
마치며: GPU 소유의 시대를 넘어, 분산 추론의 시대로
지금까지 살펴본 Ray, Ray Serve, KubeRay, 그리고 다양한 분산 서빙 기법들은 결국 하나의 목적지를 향합니다. 바로 하드웨어라는 닫힌 인프라를 어디에서나 호출할수 있는 서비스로 변환하는 일입니다.
GPU 쇼티지라는 거대한 장벽 앞에서 Aircloud가 내린 해답은 단순합니다. 더 많은 GPU를 독점하는 것이 아니라, 전 세계에 분산되어 잠들어 있는 유휴 자원을 추상화된 단일 파이프라인으로 연결하는 것입니다.
우리는 이를 위해 Kubernetes와 KubeRay로 견고한 중앙 제어 체계를 다졌고, 그 하부 구조에 대규모 이기종 장비를 유연하게 결합하는 Aircloud만의 독자적인 플랫폼 레이어를 올렸습니다. 그 결과, 유저는 지구 반대편의 GPU가 어떤 네트워크 토폴로지로 묶여 있는지 신경 쓸 필요 없이, 안정적이고 빠른 API 엔드포인트의 성능만 누리면 됩니다.
AI 인프라의 패러다임은 소유에서 가치로 이동하고 있습니다. Aircloud는 이 분산 추론 시대의 표준을 향해 계속해서 발전해 나갈 것입니다.

| Dev Team
| Author: Kitae Yoo
| Site: Linkedin


