
How to Turn GPU Resources into an Inference API
- May 29
- 7 min read
Updated: Jun 29

The Distributed GPU Cloud Story and Why Ray Is at the Center of It
💡 Core Message "A GPU that never serves a request has no business value. " Air Cloud connects everything from the runtime layer to the platform layer, so hardware actually reaches users as a real service.
Introduction
When people talk about AI infrastructure today, the conversation usually starts with GPU scarcity. How many H100s did you lock in? Is B200 supply going to loosen up? Does your data center have enough power headroom? These are real concerns, but they miss half the picture.
Yes, there is a GPU shortage. And at the same time, the GPUs that already exist are not always being used well.
Some instances are overloaded while others sit idle. Average utilization can look fine on a dashboard while a handful of nodes are doing all the work and the rest are waiting. Identical prompts hit different replicas, forcing the system to recompute prefill that has already been done somewhere else on the cluster.
The real question AI infrastructure teams should be asking has quietly shifted:
"It is not how many GPUs you own. It is how much useful output you can generate from the GPUs you have."
This post shares what AIEEV thought through while building Air Cloud, why we chose Ray as our distributed runtime, and how we use it to turn fragmented GPU resources into stable, high-throughput API capacity.
1. Why Is Running GPUs for Inference Harder Than It Looks?
The AI industry has made a definitive shift from the training era (building and refining foundation models) to the inference era (serving those models to real users at scale). The way we think about infrastructure needs to shift just as completely.
Training and inference have fundamentally different cost structures.
Training is largely a one-time, upfront expenditure: you spin up a large GPU cluster, run it hard for weeks, and you are done. Inference, by contrast, generates costs continuously and cumulatively: every user request, every agent action, every token produced adds to the bill. As a service grows, infrastructure costs scale past linear into something far steeper.
In an inference-first world, the metrics that matter are no longer about raw compute:
Metric | What it measures |
$ / request | Cost to process a single API call |
$ / token | Cost to generate a single output token |
TTFT | Time to First Token — how fast the first token reaches the user |
TPOT | Time Per Output Token — latency between successive tokens |
Throughput | Requests or tokens processed per second |
Cache hit ratio | How effectively KV cache and prefix cache are being reused |
API uptime | Reliability of the service endpoint |
Owning more GPU servers does not automatically improve any of these numbers. In LLM inference specifically, performance and cost are determined by how well you combine routing, batching, caching, placement, and autoscaling.
2. What Sits Between a GPU Server and an Inference API?
A GPU is just hardware. What users experience is not the hardware itself but the quality of the API endpoint: how quickly it responds, how reliably it stays up. To bridge that gap, four infrastructure layers need to work together:
Layer | Role |
Compute | General-purpose CPUs and AI accelerators (GPU, NPU, TPU, etc.) |
Memory / Storage | VRAM, HBM, KV cache, model weights, checkpoint management |
Network | Intra-datacenter fabric, external bandwidth, edge connectivity |
Runtime / Orchestration | Decides which AI workload runs on which hardware, in what quantity, with what parallelism strategy |
For most cloud-native workloads, Kubernetes owns the orchestration layer and does the job well.
But LLM inference workloads push past what Kubernetes alone can handle.
Serving an LLM is not like spinning up more web server containers. Model weights must stay resident in GPU memory at all times. KV cache state must be shared in real time across concurrent requests. Specific execution units inside the model need to be split and scheduled dynamically. What you need is an execution environment where AI application code and hardware resources communicate at a fine-grained level that Kubernetes was never designed to handle.
Kubernetes schedules containers and pods. AI workloads need something that can schedule model execution units directly into a distributed environment. That is where Ray comes in.
3. What Does Ray Actually Do?

Ray is a runtime for executing Python code in distributed environments.
The Ray ecosystem is layered. Ray Core is the foundational engine that handles all distributed execution. On top of it sit extension layers for specific use cases: Ray Data for large-scale data processing, Ray Serve for model serving, and others. Three concepts in Ray Core are essential to understand:
Task: The simplest execution unit. Decorate a Python function with @ray.remote , call it with .remote() , and it runs on a worker process somewhere in the cluster.
Actor: A stateful, long-lived distributed object. LLM serving requires model weights to stay loaded in GPU memory across many requests. Actor represents exactly this kind of persistent execution unit, and it is the right abstraction for keeping a model warm.
Object: Outputs from Tasks and Actors are stored in a shared Object Store and referenced by ObjectRef . Moving Objects between nodes does incur network cost, so this requires careful consideration in edge GPU environments.
⚡ The short version: Ray is not a magic fix for all infrastructure problems. It is a runtime that abstracts AI workloads into a form that distributes cleanly across many machines.
4. Ray Serve: The Layer That Turns a Model into an API
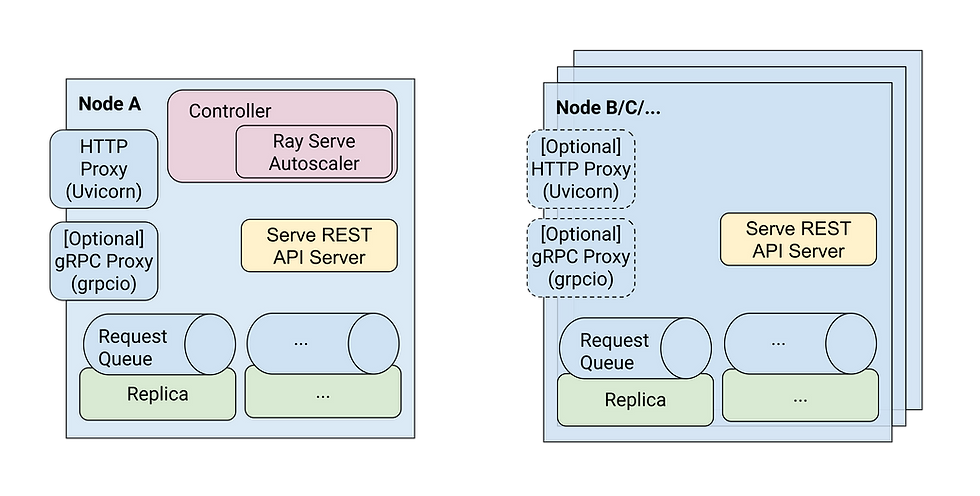
If Ray Core provides the foundation for distributed execution, Ray Serve is the framework built on top of it for serving models as HTTP or gRPC APIs.
Component | Role |
Proxy | Entry point that receives external HTTP/gRPC requests |
Controller | Control plane that manages deployment and replica state |
Deployment | A model or piece of business logic packaged as a serving unit |
Replica | An Actor instance that processes requests (holds model weights and KV cache) |
Queue | Buffer where requests wait when all replicas are busy |
Autoscaler | Monitors traffic and queue depth, adjusts replica count accordingly |
Because LLM models carry significant loading and warm-up overhead, intelligently managing the lifecycle of Replicas through Ray Serve is one of the most direct levers for reducing both latency and cost.
5. Ray Serve LLM: The Extension Layer Designed for Language Models

Ray Serve LLM sits on top of Ray Serve as an LLM-specific serving layer.
The low-level operations (actual token generation, KV cache management, continuous batching) are handled by inference engines like vLLM. Ray Serve LLM handles the orchestration on top: deciding where those engines run, how they are exposed as endpoints, and how requests route to them.
Ray Serve LLM: OpenAI-compatible API, routing, deployment management, replica lifecycle, autoscaling
vLLM / Inference Engine: Token generation, KV cache, continuous batching, GPU computation
PyTorch / NCCL / CUDA: Tensor operations, collective GPU communication, kernel execution
6. KubeRay: Connecting Ray to the Kubernetes World
The Ray ecosystem (Core to Serve to LLM) provides a powerful runtime for LLM inference. But enterprise environments also need stable deployment, monitoring, and isolation alongside existing microservices. That means Kubernetes remains the foundational standard.
KubeRay is the bridge between these two worlds.
KubeRay is a Kubernetes Operator that declaratively manages the lifecycle of Ray clusters (Ray Head and Ray Worker nodes) on top of Kubernetes. It combines the base infrastructure layer (Kubernetes) with the distributed AI execution layer (Ray), so developers can focus on serving rather than infrastructure management.
🛠️ The challenge is environmental uncertainty. A tightly controlled single datacenter is a straightforward case for standard KubeRay and Ray Serve. But Air Cloud operates across a much wider spectrum: datacenter-grade clusters, small custom server rooms, enterprise AI workstations, and geographically scattered consumer GPUs. Hardware topology and cluster scale vary dramatically across every connected resource. Applying the same serving strategy to every GPU in this environment is not workable. Air Cloud solves this by continuously monitoring the scale and network state of every connected resource, then dynamically assembling the optimal combination of scheduling, routing, and parallelism strategies for each workload, topology-aware, in real time.
7. Air Cloud Strategy
① Topology-Aware Scheduling and Parallelism
Air Cloud reads the characteristics of incoming workloads and the hardware topology of available GPUs in real time, then selects and applies the parallelism strategy best suited to that specific environment.
GPU Infrastructure Tier | Air Cloud Optimization Strategy |
High-speed network fabric: datacenter and small clusters |
|
Single-node multi-GPU workstations |
|
Geographically distributed edge and consumer GPU pools |
|
For example, on a cluster with guaranteed high bandwidth, Air Cloud applies aggressive distributed strategies to maximize compute efficiency. On isolated workstations or consumer GPUs, it schedules workloads that can be processed entirely within a single node, eliminating network bottlenecks entirely.
② Intelligent Routing and Prefill-Decode Optimization
LLM inference breaks into two distinct phases (setting aside model loading):
Prefill: The model reads the entire input prompt and runs compute-heavy attention to build the KV cache. Compute-bound.
Decode: The model generates tokens one at a time by reading the KV cache. Memory-bandwidth-bound.
Air Cloud applies completely different routing mechanisms for these two phases depending on the network characteristics of the connected infrastructure.
High-speed network environments with cluster-grade bandwidth (PD Disaggregation): When the network can transfer large KV caches with negligible latency, Air Cloud physically separates Prefill nodes from Decode nodes. This disaggregated architecture maximizes system throughput.
Loose-network edge and single-GPU environments (Prefix-Aware Routing): Moving large KV caches across a slow network is itself a major overhead. Instead of moving data, Air Cloud routes each request to the warm replica most likely to already hold the matching KV cache for that system prompt or context prefix. Minimizing cache misses cuts TTFT dramatically without any network transfer cost.
💡 The core of Air Cloud is this: no matter what hardware connects to the platform, Air Cloud continuously reads the network bandwidth and compute capacity of every resource, then dynamically assembles the architecture (Data Parallel, PD Disaggregation, Prefix-Aware Routing, and others) that delivers the best combination of cost efficiency and performance for that specific workload.
Closing: From GPU Ownership to Distributed Inference
All the pieces discussed here (Ray, Ray Serve, KubeRay, and the various distributed serving techniques) point toward a single destination: turning closed hardware infrastructure into a service that can be called from anywhere.
Faced with the structural reality of GPU scarcity, Air Cloud reached a straightforward answer. The goal is not to accumulate more GPUs through exclusivity. It is to connect the idle, fragmented resources distributed across the world into a single abstracted pipeline.
To do that, we built a solid central control plane with Kubernetes and KubeRay. On top of that foundation, we layered Air Cloud's own platform logic for flexibly integrating heterogeneous hardware at scale. The result: users do not need to know anything about the network topology of a GPU on the other side of the world. They just get a fast, stable API endpoint.
The AI infrastructure paradigm is moving from ownership to value creation. Air Cloud will keep pushing forward toward the standard for this distributed inference era.

| Dev Team
| Author: Kitae Yoo
| Site: Linkedin


